
现在Unicode已然一统天下,我想很多年轻的程序员可能都没遇到过编码问题,更不用说了解编码的发展了。前些日子在一个老网站上偶遇乱码,虽然入行时间不短,但对其究竟也是不甚了解,好奇心驱使下落入深坑。还好经过一段时间的摸爬滚打,边学边写,总算大概理清了个脉络,记录之,分享之。
概念
字符是一个信息单位,在计算机里面,一个中文汉字是一个字符,一个英文字母是一个字符,一个阿拉伯数字是一个字符,一个标点符号也是一个字符。
字符集是字符组成的集合,通常以二维表的形式存在,二维表的内容和大小是由使用者的语言而定,是英语,是汉语,还是阿拉伯语。
字符编码是把字符集中的字符编码为特定的二进制数,以便在计算机中存储。编码方式一般就是对二维表的横纵坐标进行变换的算法。一般都比较简单,直接把横纵坐标拼一起就完事了。后来随着字符集的不断扩大,为了节省存储空间,才出现了各种各样的算法。
字符集和字符编码一般都是成对出现的,如ASCII、IOS-8859-1、GB2312、GBK,都是即表示了字符集又表示了对应的字符编码,以后统称为编码。Unicode比较特殊,后面细说。
发展
单字节
计算机是美国人发明的,人家用的是美式英语,字符比较少,所以一开始就设计了一个不大的二维表,128个字符,取名叫ASCII(American Standard Code for Information Interchange)。128个码位,用7位二进制数表示,由于计算机1个字节是8位二进制数,所以最高位为0,即00000000-01111111或0x00-0x7F。

后来美国人发现128个码位不够用,于是在原来二维表的基础上进行了扩展,256个字符,取名叫EASCII(Extended ASCII)。256个码位,用8位二进制数表示,即00000000-11111111或0x00-0xFF。

当计算机传到了欧洲,美国人的标准不适用了,但是改改还能凑合。于是国际标准化组织在ASCII的基础上进行了扩展,形成了ISO-8859标准,跟EASCII类似,兼容ASCII,在高128个码位上有所区别。但是由于欧洲的语言环境十分复杂,所以根据各地区的语言又形成了很多子标准,ISO-8859-1、ISO-8859-2、ISO-8859-3、……、ISO-8859-16,真是令人发指。
双字节
当计算机传到了亚洲,尤其是东亚,国际标准被秒杀了,路边小孩随便说句话,256个码位就不够用了。于是乎继续扩大二维表,单字节改双字节,16位二进制数,65536个码位。在不同国家和地区又出现了很多编码,大陆的GB2312、港台的BIG5、日本的Shift JIS等等。
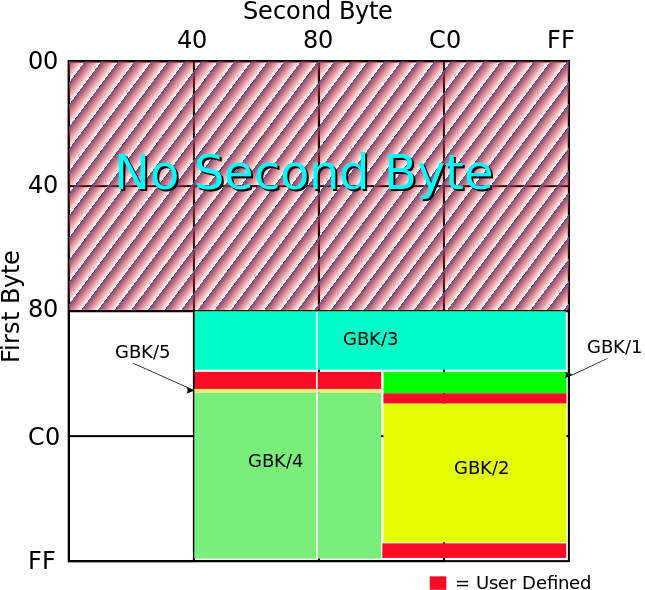
注意65536个码位这种说法只是理想情况,由于双字节编码可以是变长的,也就是说同一个编码里面有些字符是单字节表示,有些字符是双字节表示。这样做的好处是,一方面可以兼容ASCII,另一方面可以节省存储容量,代价就是会损失一部分码位。而且编码的设计也并不是想象的那样,所有字符从头到尾布满整个二维表,都是有预留空间的。比如说GBK是GB2312的扩展(K竟然是拼音KuoZhan的缩写),按理说都属于双字节编码,码位是一样的,根本谈不上扩展,但实际上是预留空间在起作用。比如下图为GBK的编码空间,GBK/1、GBK/2是GB2312的区域,GBK/3、GBK/4、GBK/5是GBK的区域,红色是用户自定义区域,白色可能就是由于变长编码损失的区域了。
Unicode
当互联网席卷了全球,地域限制被打破了,不同国家和地区的计算机在交换数据的过程中,就会出现乱码的问题,跟语言上的地理隔离差不多。乱码是怎么出现的呢?对同一组二进制数据,不同的编码会解析出不同的字符,用对了编码,解析出来的字符组成的文字是有意义的,用错了编码,解析出来的字符组成的文字是没意义的,也就是通常所说的乱码。
经过之前的介绍,编码很多,全球的计算机们没办法在一起好好的玩耍。要彻底解决这个问题,替代原先基于语言的编码系统,就需要一个通用的字符集UCS(Universal Character Set)和一个通用的字符编码Unicode。一开始UCS用2个字节表示,叫做UCS-2,后来2个字节不够用,于是就用4个字节,叫做UCS-4。但是如果每一个字符都用4个字节来表示的话,相较之前的编码会浪费很多存储空间,尤其是相对ASCII等单字节编码会非常吃亏。并且当时已经有些厂商在双字节编码上投入了很大的精力。于是UTF-16就被作为一种折中的方案提了出来,既保持了两字节不变,又保证了足够的编码空间。而UTF-32是与UCS-4相对应的,UTF-8则由于扩展性比较强,从容应对了UCS-2到UCS-4的改变。关于各种UTF的实现细节可以点击链接查看(翻墙),已经说得很清楚了,就不赘述了,但不得不提一下,UTF-16的设计还挺巧妙的。
UTF(Unicode Transformation Format)是将Unicode编码进行了转换,通常会在存储空间和效率上进行一定的权衡,有很多种实现方式,前面提到了UTF-8和UTF-16是最常用的。这就是之前提到的Unicode的特殊之处。
历史
ASCII
1960 开发
1963 发布
1986 最后一次更新ISO-8859-1
1998 发布GB2312
1980 发布GBK
1993 发布UCS-2
In the late 1980sUnicode
1987 开发
1991 发布
1996 实现代理机制(UTF-16)
2015 最新版8.0UTF-8
1993 发布
2008 流行UTF-16
1996 开发
2000 发布
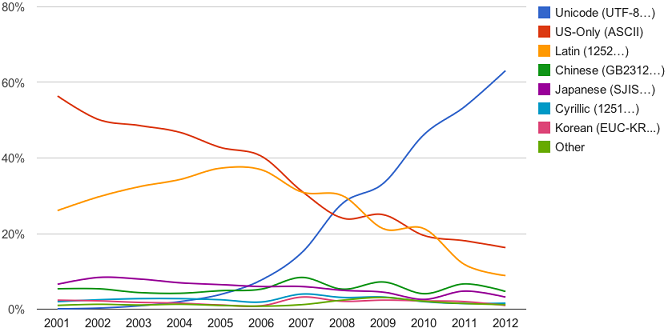
根据以上各个编码发展的一些时间节点,再配合下图UTF-8制霸互联网过程,会有一个比较清晰的了解。
尾声
虽然Unicode解决了地球上的问题,但是以后三体人入侵可怎么办,根据这些天研究编码发展历史来看,比较靠谱的回答——还是到时再说吧。
本文是根据互联网上各种信息来源,主要是维基百科,加上自己的理解,进行的总结和演绎,肯定有不准确或错误的地方,还望不吝赐教。